How Git-Xet storage works
The Git-Xet extension uses .gitattributes to take over responsibility of
data storage for all files in a given repository, except for the .gitattributes file itself,
and the contents of a .xet configuration folder.
* filter=xet diff=xet merge=xet -text
*.gitattributes filter=
*.xet/** filter=
This allows us to take over management of all the data (contents of files), while letting Git handle the metadata (file system layout). However, as Git is remarkably good at handling small text files, we automatically pass through text files below 256 KB to Git -- which should include almost all source code.
Pointer Files
We deem files that are non-UTF-8 decodeable or larger than 256 KB valuable for
deduplication. When such a file is checked into the repository using git add,
we run our deduplication algorithm against the file content. The deduplicated
data is then transferred to our managed storage service that are optimized for
large objects. The metadata of the file content, which essentially contains a
one-to-one mapping cryptographically secure hash, is written back to the file
and checked into the repository.
We call such translated files pointer files because they, like pointers in
programming languages, occupy constant storage size in the repository for however
large the actual data they point to. When a pointer file is checked out, we find
the actual data using the hash and materialize it in the working directory -- a
process we call smudge.
Merkle Trees
Our data storage system is a data deduplication method built on top of a Content Addressed Store (CAS) which balances the need for large objects (which are more efficient to store, communicate and manage) as well as efficient data deduplication on small block sizes.
The core datastructure underlying the data deduplication method is a Content Defined Merkle Tree (CDMT).
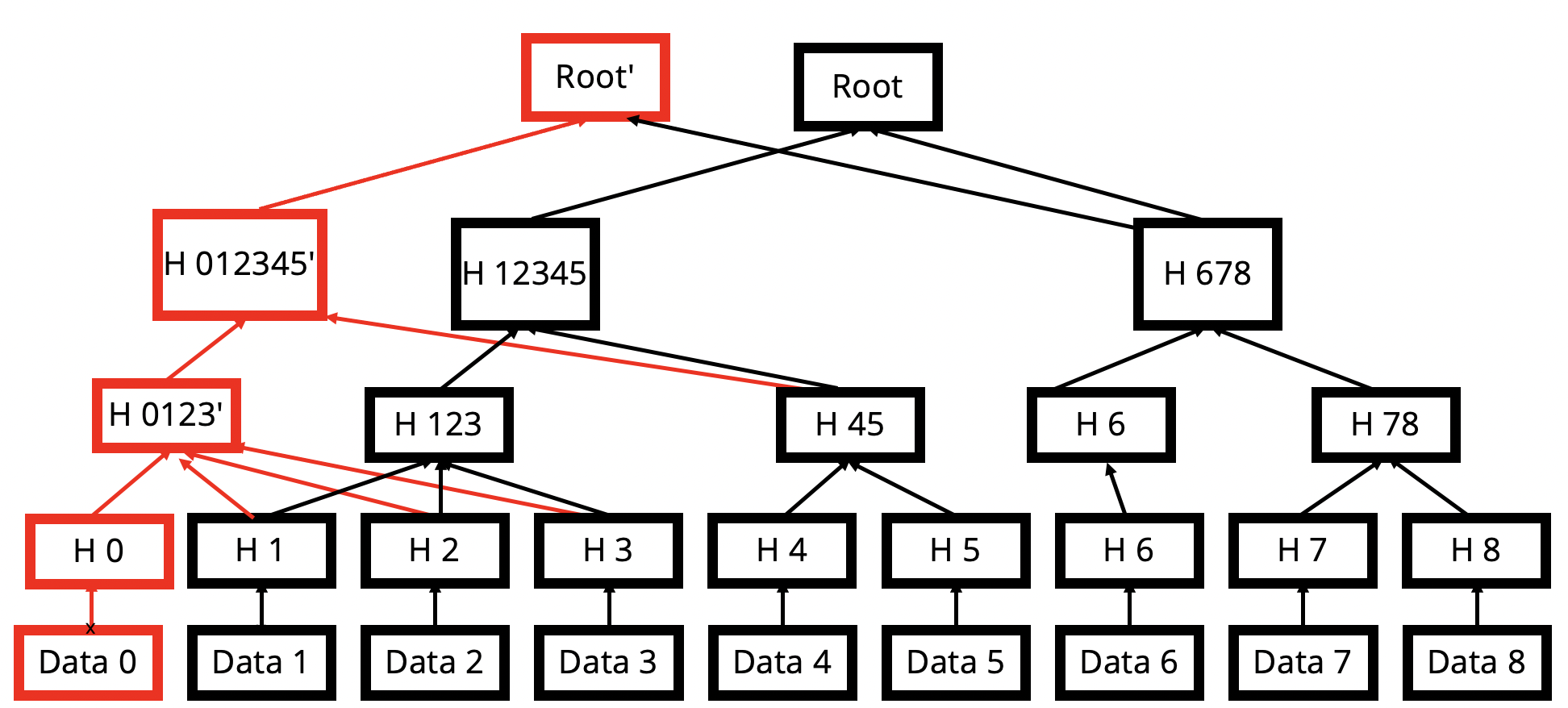
Each file is cut into small variable sized chunks with an average of 16 KB per chunk. A MerkleTree is built by grouping chunk hashes together also using Content Defined Chunking. As such, operations such as insertions, deletions or modifications of chunks do not substantially rewrite the tree, allowing most of the tree to be preserved across chunks. For instance, in the image above, the insertion of new bytes at the start of the file may only add a small number of nodes to the tree.
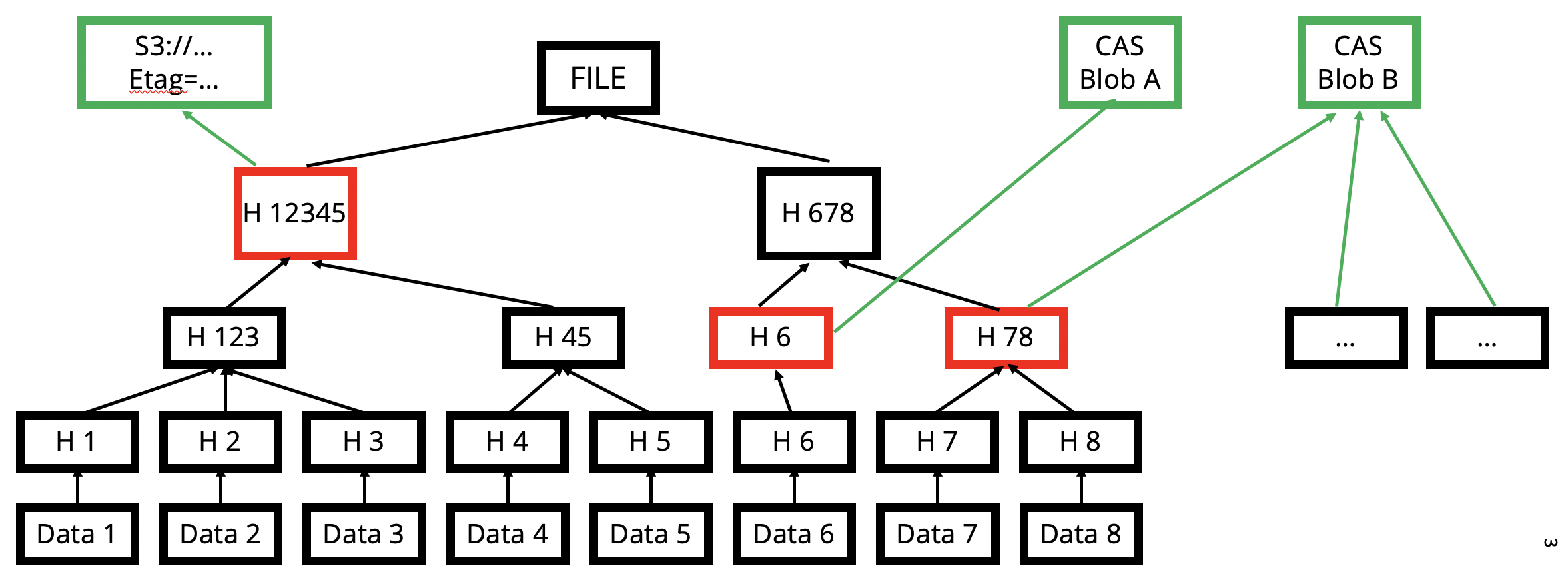
Data Blocks
When files are added, any new chunks are concatenated together into 16 MB blocks, and a separate MerkleTree is used to represent the block and all the chunks it contains. To reconstruct any file, a graph traversal is performed to intersect the file tree with the block tree, which resolves the set of block ranges needed to reconstruct the file.
These large block sizes have a huge amount of data locality (likelihood of needing the whole block when accessing part of a block) and are much more efficient to send and receive allowing for great performance.
Block Caching
For efficiency, block reads are cached locally so that switching checked-out versions can be performed quickly without re-downloading much. The cache size can be inspected with the following command. (Your values may differ.)
git xet cas status
CAS remote: cas-lb.xethub.com:5000
CAS prefix: default
Cache Size: 1.69 GB / 10.74 GB
Staging Size: 0 bytes
The cache size can be changed with the git xet config command.
This will set it to 10 GB.
git xet config --global cas.cache 10737418240 # (value in bytes)
Internal Details
The MerkleTrees are stored in Git itself using git notes. It behaves like a parallel worktree that is inside the same repository. As the MerkleDB is typically quite small (~1% of the size of the repo), this is acceptable and optimizations can be made in the future.
You can explore the Merkle Tree with a collection of plumbing commands.
For instance, you can clone our sample repository of the
LAION-400M dataset
with the argument --lazy to keep everything in the original pointer
file format stored by Git, rather than our default behavior of materializing all files.
git xet clone --lazy https://xethub.com/XetHub/LAION-400M
cd LAION-400M
Pointer Files
We can see the pointer file contents:
$ cat part-00000-5b54c5d5-bbcf-484d-a2ce-0d6f73df1a36-c000.snappy.parquet
# xet version 0
filesize = 1803288490
hash = '5b4522b02942fb5e0584ed9d098f92952cfa79c30b88f3a880233afaae7a0936'
MerkleDB Query
And query the hash in the file with the git xet plumbing command and
we see the set of block hashes and ranges required to reconstruct the file.
$ git xet merkledb query .git/xet/merkledb.db 5b4522b02942fb5e0584ed9d098f92952cfa79c30b88f3a880233afaae7a0936
5b4522b02942fb5e0584ed9d098f92952cfa79c30b88f3a880233afaae7a0936:
len:1803288490
children:["586ba97b2cf42156d3d36e9069ad4a3c92cf710f1186fdbf3ce3e61a022bf276",
"cd2ae428a7ed0d028c9cb2a034ca9c504041e5a0ca960a683660224ca381bf01",
"29eaefd943762d4607bbcd27594338dd1290bbfca94249ef2545aacdd84d7496",
"2cecabe82a422126151f95e962601ccf8f884b90c04899c0777289f7d1be53df"]
attr:"MerkleNodeAttributes { parent: [0, 0], attributes: FILE }"
Substring [0, 1803288490) of FILE entry 5b4522b02942fb5e0584ed9d098f92952cfa79c30b88f3a880233afaae7a0936
CAS Reconstruction: [(5b4522b02942fb5e0584ed9d098f92952cfa79c30b88f3a880233afaae7a0936,
[ObjectRange { hash: b1fde64301ba5cbbdcba3052c308cb69814edb83eab48ad042a57e663df90c89, start: 0, end: 15735931 },
ObjectRange { hash: 5b296cc82fd9f4c85c3351d21b6a097b4725ededdd3d4a19d709359d1f3a91c5, start: 0, end: 15728954 },
ObjectRange { hash: ae30d0225c3c65d0a4f8509d9ff88f60339078ff7e80538fd3e6f128e42b49e2, start: 0, end: 15736673 },
ObjectRange { hash: 7decda136dbee1bd6bb4452133dbd58709ea44734174434a09f3c1e5e6387f1c, start: 0, end: 15733539 },
ObjectRange { hash: f5f289032c9d7eaa95000c266b6b7c7ff2087ee33c4821a27c7e2df612c7cb43, start: 0, end: 15745882 },
... ])]
Statistics
To see the deduplication statistics for any commit in a repository, you can use the following plumbing command from the repository root directory:
git xet merkledb stat <commit id>
This will print out a summary that looks something like this:
$ git xet merkledb stat HEAD
Summary
-------
New blocks created: 1 blocks
Total bytes in new blocks: 19113 bytes
Total size of all modified files: 365655841 bytes
File bytes reused from prior blocks: 365636728 bytes
File bytes in new blocks: 19113 bytes
Bytes saved to intra-commit deduplication: 0 bytes
In the example above, which involved a change to the row header, only 19113 bytes was required to represent the change, as opposed to uploading the whole 350 MB file.