November 20, 2024
From Files to Chunks: Improving HF Storage Efficiency



Hugging Face stores over 30 PB of models, datasets, and spaces in Git LFS repositories. Because Git stores and versions at the file level, any change to a file requires re-uploading the full asset – expensive operations when average Parquet and CSV files on the Hub range between 200-300 MB, average Safetensor files around 1 GB, and GGUF files can exceed 8 GB. Imagine modifying just a single line of metadata in a GGUF file and waiting for the multi-gigabyte file to upload; in addition to user time and transfer costs, Git LFS also then needs to save full versions of both files, bloating storage costs.
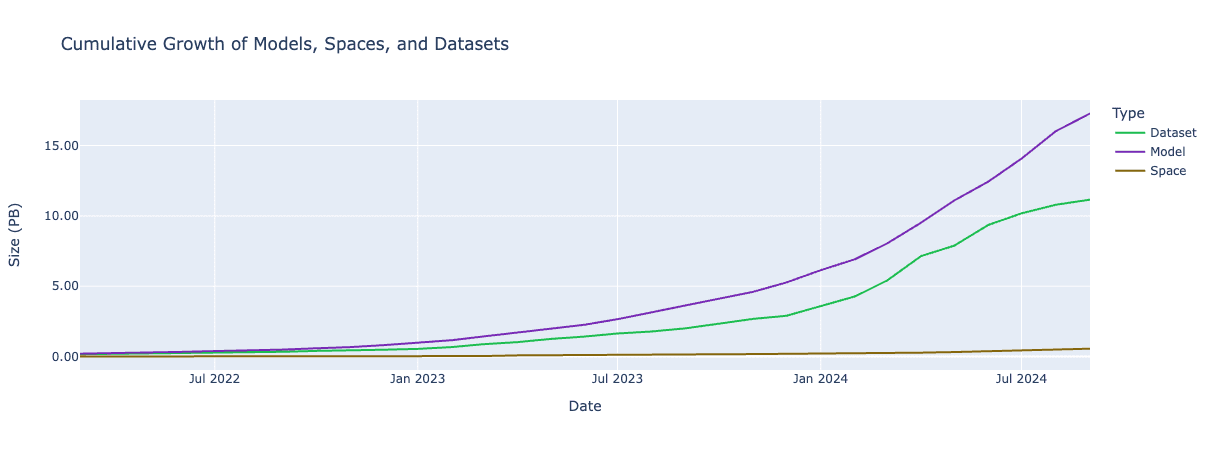
The plot below illustrates the growth of LFS storage in model, dataset, and space repositories on the Hub between March 2022 and September 2024:
Hugging Face's Xet team is taking a different approach to storage by storing files as chunks. By only transferring modified chunks, we can dramatically improve both storage efficiency and iteration speed while ensuring reliable access to evolving datasets and models. Here’s how it works.
Content-Defined Chunking Foundations
The method that we use to chunk files is called content-defined chunking (CDC). Instead of treating a file as an indivisible unit, CDC breaks files down into variable-sized chunks, using the data to define boundaries. To compute the chunks, we apply a rolling hash algorithm that scans the file’s byte sequence.
Consider a file with the contents:
We’re using text for illustration, but this could be any sequence of bytes.
A rolling hash algorithm computes a hash over a sliding window of data. In this case, with a window of length 4 the hash would be computed first over tran, then rans, then ansf and so on until the end of the file.
Chunk boundaries are determined when a hash satisfies a predefined condition, such as:
If the sequence mers produces a hash that meets this condition, the file will be split into three chunks:
The content of these chunks is hashed to create mapping between chunk hash and bytes and will eventually be stored in a content-addressed store (CAS). Since all three chunks are identical, we only store one chunk in the CAS for built-in deduplication. 🪄
Insertions and Deletions
When the contents of a file change, CDC allows for fine-grained updates that make it robust to handling insertions and deletions. Let’s modify the file by inserting `super`, making the new file contents:
After applying the rolling hash again with the same boundary condition, the new chunks look like this:
We do not need to save chunks we have seen before; they are already stored. However, supertransformers is a new chunk. Thus, the only cost of saving the updated version of this file is uploading and storing one new chunk.
To validate this optimization in the real world, we benchmarked our previous implementation of CDC-backed storage at XetHub against Git LFS and found a consistent 50% improvement in storage and transfer performance across three iterative development use cases. One example was the CORD-19 dataset, a collection of COVID-19 research papers curated between 2020 and 2022 with 50 incremental updates. The comparison between Xet-backed and Git LFS-backed repositories is summarized below:
By only transferring and saving modified chunks, the Xet-backed repository using CDC (alongside various techniques to improve compression and streamline network requests) showed significantly faster upload/download times and drastically cut the amount of storage required to capture all versions of the dataset. Curious to learn more? Read the full benchmark.
What CDC means for the Hub
How would CDC work on the types of files stored on Hugging Face Hub? We threw together a simple deduplication estimator to visualize the potential storage savings of applying CDC to a collection of files. Running this tool on two versions of the model.safetensors file in openai-community/gpt2 uploaded over the course of the repository's commit history returned the following result:

The greenness reflects significant overlap between the two versions, and thus an opportunity to deduplicate both within each file and across the versions.
In this case, using our Xet-based storage backend would save considerable upload/download time for the second version, as well as reduce the total storage footprint by 53%. With compression, we estimate an additional 10% of savings.
Our initial research into repositories across the Hub shows positive results for some fine-tuned models and many model checkpoints. Fine-tuned models modify only a subset of parameters, so most of the model remains unchanged across versions, making them a great candidate for deduplication. Model checkpoints, which capture incremental training states, are also good targets as changes between checkpoints are often minimal. Both show deduplication ratios in the range of 30-85%. PyTorch model checkpoints make up around 200 TB of total storage on the Hub. At 50% deduplication, we would save up to 100 TB of storage immediately and roughly 7-8 TB monthly going forward.
Beyond reducing storage costs, chunk-level deduplication also improves upload/download speeds, as only the modified chunks are transferred. This is a great benefit to teams working with multiple versions of models or datasets as it minimizes user and machine waiting time.
Our team is currently working through our POC of Xet-backed storage for the Hub and hope to roll out some Xet-backed repositories in early 2025.
This post was originally published on the Hugging Face blog. Follow our team on Hugging Face to keep up with all new updates as we share our learnings on scaling CDC across globally distributed repositories, balancing network performance, privacy boundaries, and parallelizing our chunking algorithm.
Share on


