October 1, 2024
Shutting down XetHub: Learnings and Takeaways


This morning, we tore down the servers for our XetHub product after 658 days in production. It’s as good a time as any to reflect on what we learned.
What we thought we knew
From the start, our team’s mission was to “make collaboration on big data delightful” and we launched a product to meet that challenge. Our initial offering targeted ML teams, and was developed around three basic tenets:
Git for ML collaboration: Much like Git for code, once something is stored, we should only need to store the changes between versions - even for binary files. Since developers already upload, download, and work together with Git-based tooling, we can simply extend Git to work with larger ML files for full reproducibility and provenance.
Flexible file support: ML data and models come in all shapes and sizes. By adopting file-system semantics in our architecture and supporting all file types, we have the ability to optimize by file type to improve performance.
Instant reads, faster writes: Use file-system mounts to stream data instead of always downloading it, making access almost instant and saving lots of compute hours. Deduplicating changes (like Git) would make iterative writes faster, avoiding re-uploading things that haven’t changed.
We figured that If we nailed these three home runs, companies would flock to our product. Who wouldn’t sign up for a faster, more scalable Git product that made ML more collaborative?
So we picked up Gitea, an open source GitHub alternative, stood up infrastructure with our AWS startup credits, and got to work. After 10 months of development, we hit #3 on the front page of Hacker News on our first try, quickly signed our first paying customer, and figured that we had made it!
What we didn’t know

Alas. Here are some hard truths we encountered:
Git outta here! I’m not changing my workflow.
ML engineers and data scientists aren’t always software engineers - or if they are, are not as indoctrinated to Git as we thought they’d be. And as easy as our extension made it to work with big files in Git (no extra commands, just magically works!), people who already had a functional workflow — no matter how janky or awkward — did not want to invest in revamping something that wasn’t completely broken.
Takeaway: Much like physically moving, moving workflows is a PITA and is not worth the investment if there isn’t enough pain.Data inertia is real.
Storing data in S3 is easy. Getting approval and budget to move existing data into a new data storage system is not. We got SOC2 certified, but most conversations stalled when the prospects realized that they would need to store their data in our system to experience all of the benefits. To combat this, we provided a self-hosted option that closed some deals, but this was only appealing to emerging teams who were building a workflow from scratch (see point 1 above). Putting private data into a startup’s data system was yet another layer of difficulty on top of general inertia, and the cost savings of deduplication and streaming were not worth the risk. Additionally, ML teams often don’t run their own infrastructure, so the selling motion was never simple, requiring buy-in across organizations.
Takeaway: Selling a product that requires high user investment to show value is hard.ML best practices are still maturing.
At Apple, where most of our founding team built the internal ML platform, ML reproducibility and governance was taken very seriously, since feature teams were held accountable for why their models made certain decisions — things that needed to be traced back to potential errors in inputs, annotations, or training data. The strictness of Git-based change accountability enables perfect provenance, and we thought that would be a strong selling point. However, as ML becomes more pervasive through various industries, few of the prospects we talked to shared that perspective. Model provenance and reproducibility? Those sound nice! But we don’t need that. And they’re right: some industries (supply chain logistics come to mind) use rolling data where having a good model in production is enough. Looking backwards will never be a priority.
Takeaway: Don’t assume that everyone cares about what you think they should care about.
There are many more learnings, of course — how difficult it is to build a community from scratch, the roller coaster ride of enterprise partnerships, the never-ending fight against spam accounts, how no one knows how to pronounce “XetHub” — but these top three kept hitting us over and over.
Near the end, we realized that while our technology was great, users only realized the benefits when they could directly experience an interaction. The most resonant features we had weren’t ones of Git-compatibility and fast access, as we had assumed, but ones that were a level abstracted: features that made it easy for users to track the evolution of their work and review it with others, going beyond the solo player to building a collaborative team. But while we had several satisfied customers and promising partnerships in the pipeline, gaining traction was still an uphill battle.
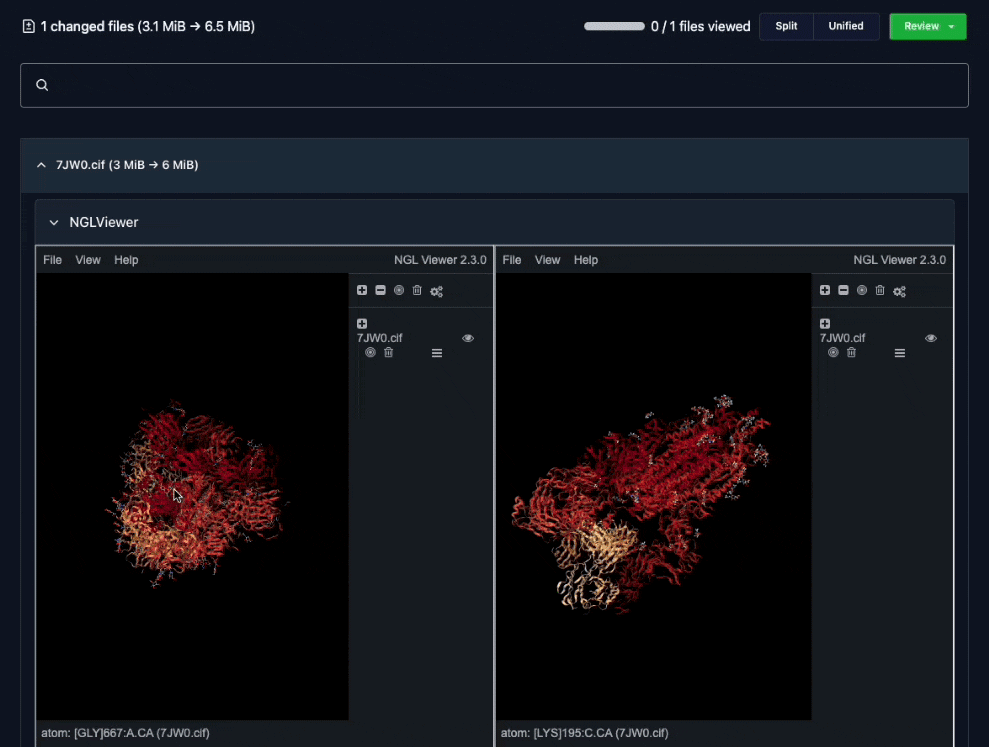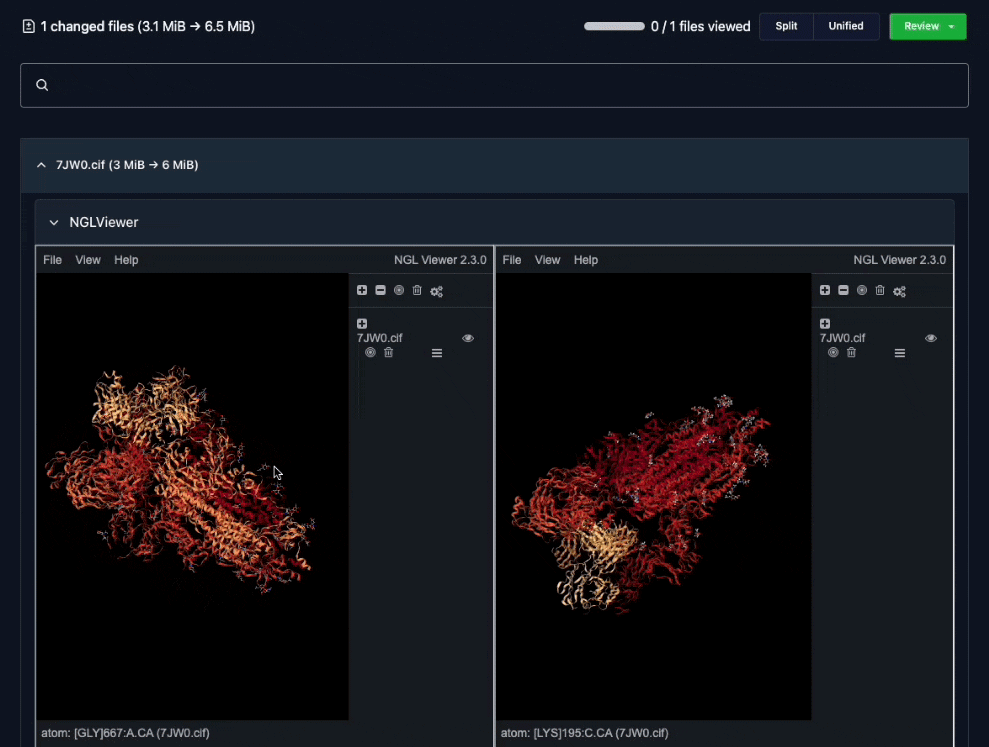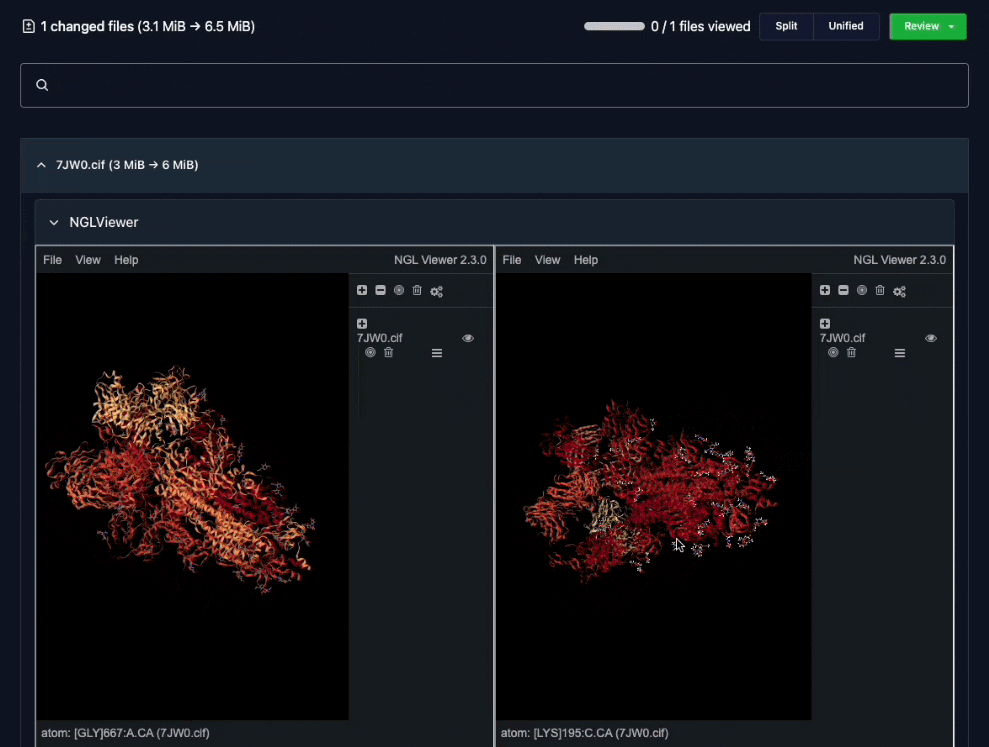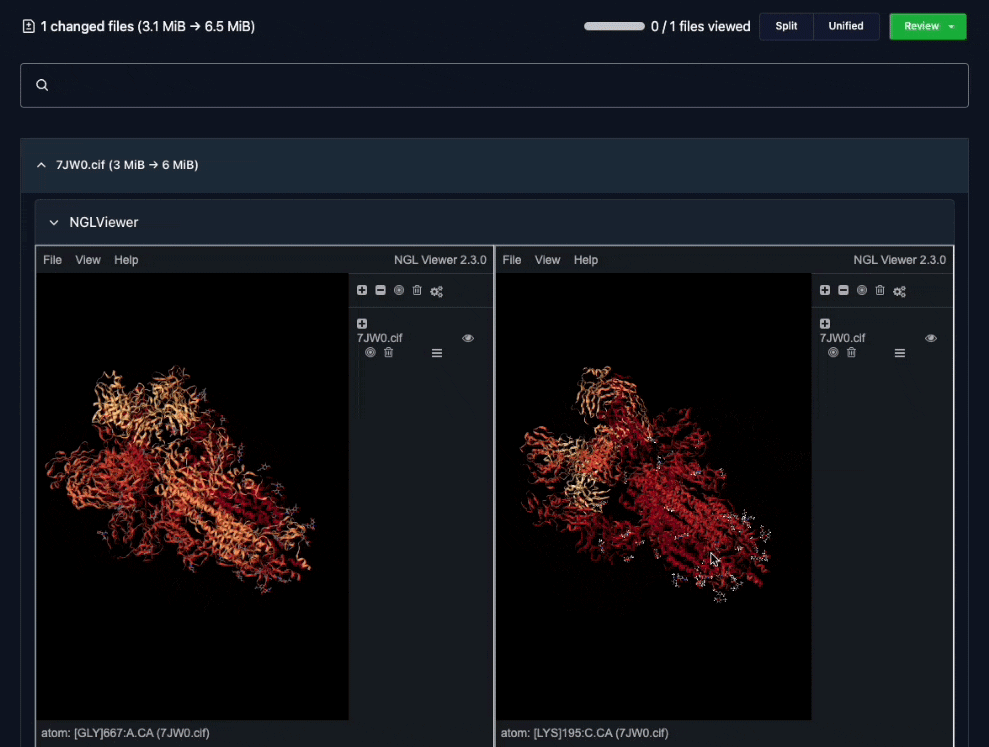
Custom difference views made it easy for teams to review changes together.
What next?
We were contemplating options for raising our next round of funding when Hugging Face CTO Julien Chaumond reached out to start a conversation. His interest in leveraging our backend architecture and deduplication features to improve ML developer experience made perfect sense, and we resonated with Hugging Face’s mission of being “the AI community building the future”. After some great discussions, we came to an agreement.
Interestingly enough, Hugging Face had already anticipated or overcome the challenges we identified above:
Many Hugging Face users use the Hub’s client library, which abstracts away some of the pain of their current Git LFS backend, rather than directly using Git. We could replace Git LFS with our more scalable and performant backend without any user workflow changes. Views like the model tree enable users to see the provenance of a model without dependence on commit history, opening the doors for more flexible versioning.
With over 1 million models and over 30 PBs of models, datasets, and spaces, people are already sharing their files on the Hugging Face Hub. What data inertia? It’s a trove of open ML development at scale where we can add value, with an Enterprise offering that guarantees the security and audit controls that large companies need to confidently do business.
ML best practices are constantly in the process of being established by the open source ML community on the Hugging Face platform. From the basics of model and dataset cards to considering what can be done to improve ML transparency (see Ethics lead Margaret Mitchell’s most recent Senate testimony), we want to be a part of the solution.
We can’t help but wax nostalgic about our 2.5 years of building XetHub, but joining Hugging Face in August has given us a new chance to “make collaboration on big data delightful” for the largest AI community in the world.
XetHub is dead. Long live the Hub!
Just recently, we shared our first internal demo of a Xet-backed file round-trip through Hugging Face infra. We’re grateful to have landed in a company with such a passion for open sharing, and are looking forward to designing in public as we reconsider our approaches to content-defined chunking, deduplication over private data, and more.
While our first order of business is to replace Git LFS as Hugging Face’s storage backend to speed up all file transfers, we can’t wait to build upon that foundation to introduce better developer experiences to all users of the Hub. Follow our team to stay tuned and reach out if you have any ideas!
Share on


