November 25, 2024
Rearchitecting Hugging Face Uploads and Downloads



As part of Hugging Face's Xet team’s work to improve Hugging Face Hub’s storage backend, we analyzed a 24 hour window of Hugging Face upload requests to better understand access patterns. On October 11th, 2024, we saw:
Uploads from 88 countries
8.2 million upload requests
130.8 TB of data transferred
The map below visualizes this activity, with countries colored by bytes uploaded per hour.
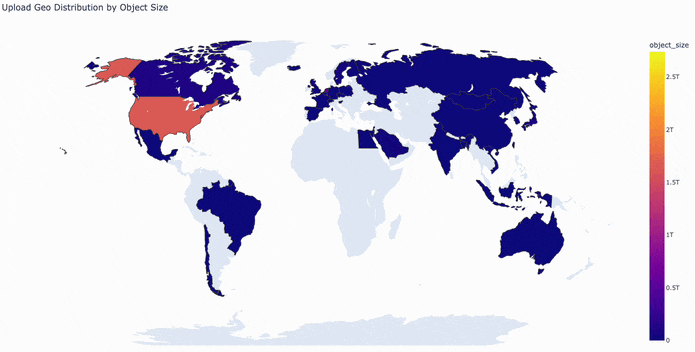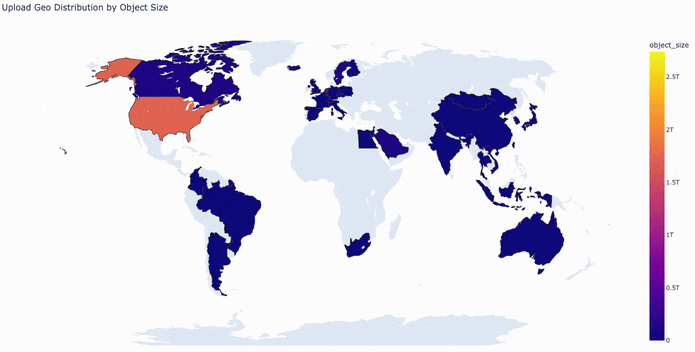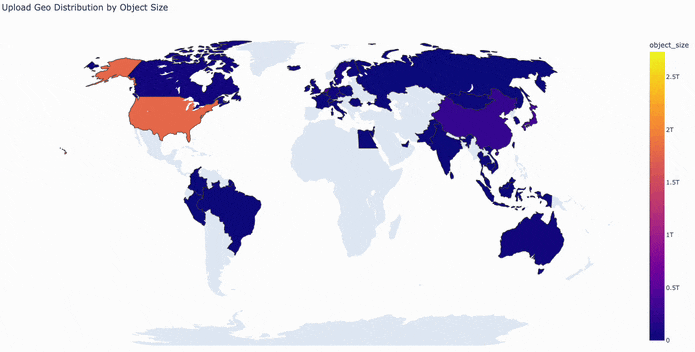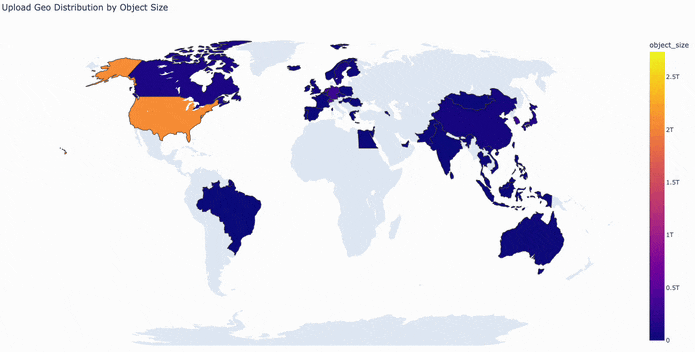
Currently, uploads are stored in an S3 bucket in us-east-1 and optimized using S3 Transfer Acceleration. Downloads are cached and served using AWS Cloudfront as a CDN. Cloudfront’s 400+ convenient edge locations provide global coverage and low-latency data transfers. However, like most CDNs, it is optimized for web content and has a file size limit of 50GB.
While this size restriction is reasonable for typical internet file transfers, the ever-growing size of files in model and dataset repositories presents a challenge. For instance, the weights of meta-llama/Meta-Llama-3-70B total 131GB and are split across 30 files to meet the Hub’s recommendation of chunking weights into 20 GB segments. Additionally, to enable advanced deduplication or compression techniques for both uploads and downloads requires a reimagining of how we handle file transfers.
A Custom Protocol for Uploads and Downloads
To push Hugging Face infrastructure beyond its current limits, we are redesigning the Hub’s upload and download architecture. We plan to insert a content-addressed store (CAS) as the first stop for content distribution. This enables us to implement a custom protocol built on a guiding philosophy of dumb reads and smart writes. Unlike Git LFS, which treats files as opaque blobs, our approach analyzes files at the byte level, uncovering opportunities to improve transfer speeds for the massive files found in model and dataset repositories.
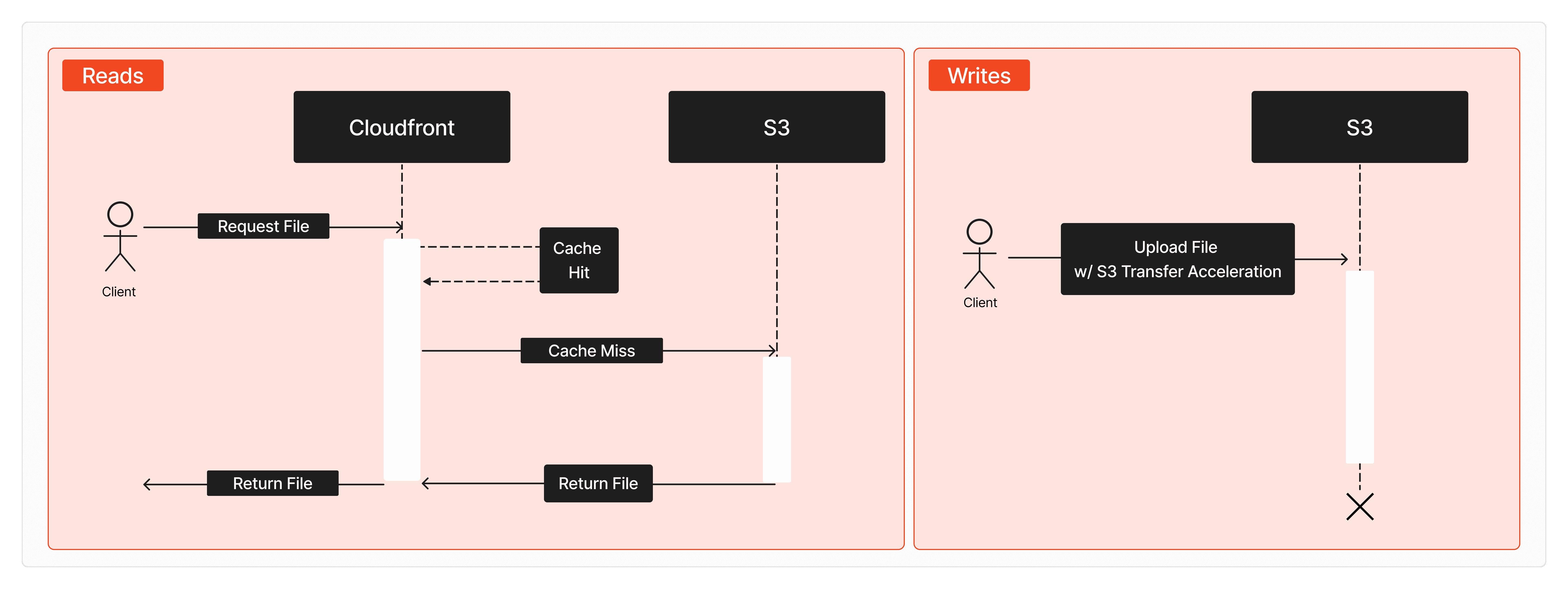
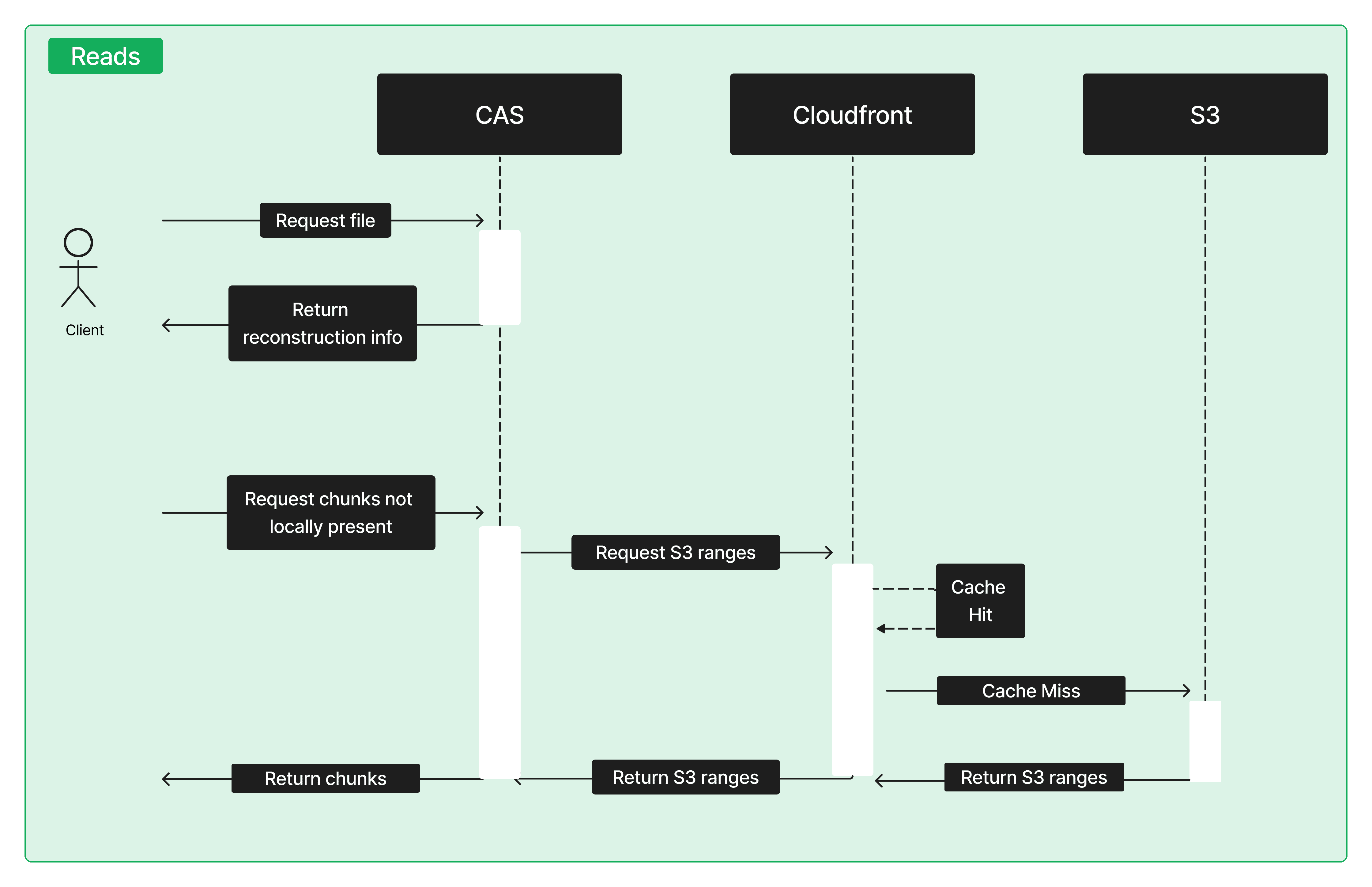
The read path prioritizes simplicity and speed to ensure high throughput with minimal latency. Requests for a file are routed to a CAS server, which provides reconstruction information. The data itself remains backed by an S3 bucket in us-east-1, with AWS CloudFront continuing to serve as the CDN for downloads.
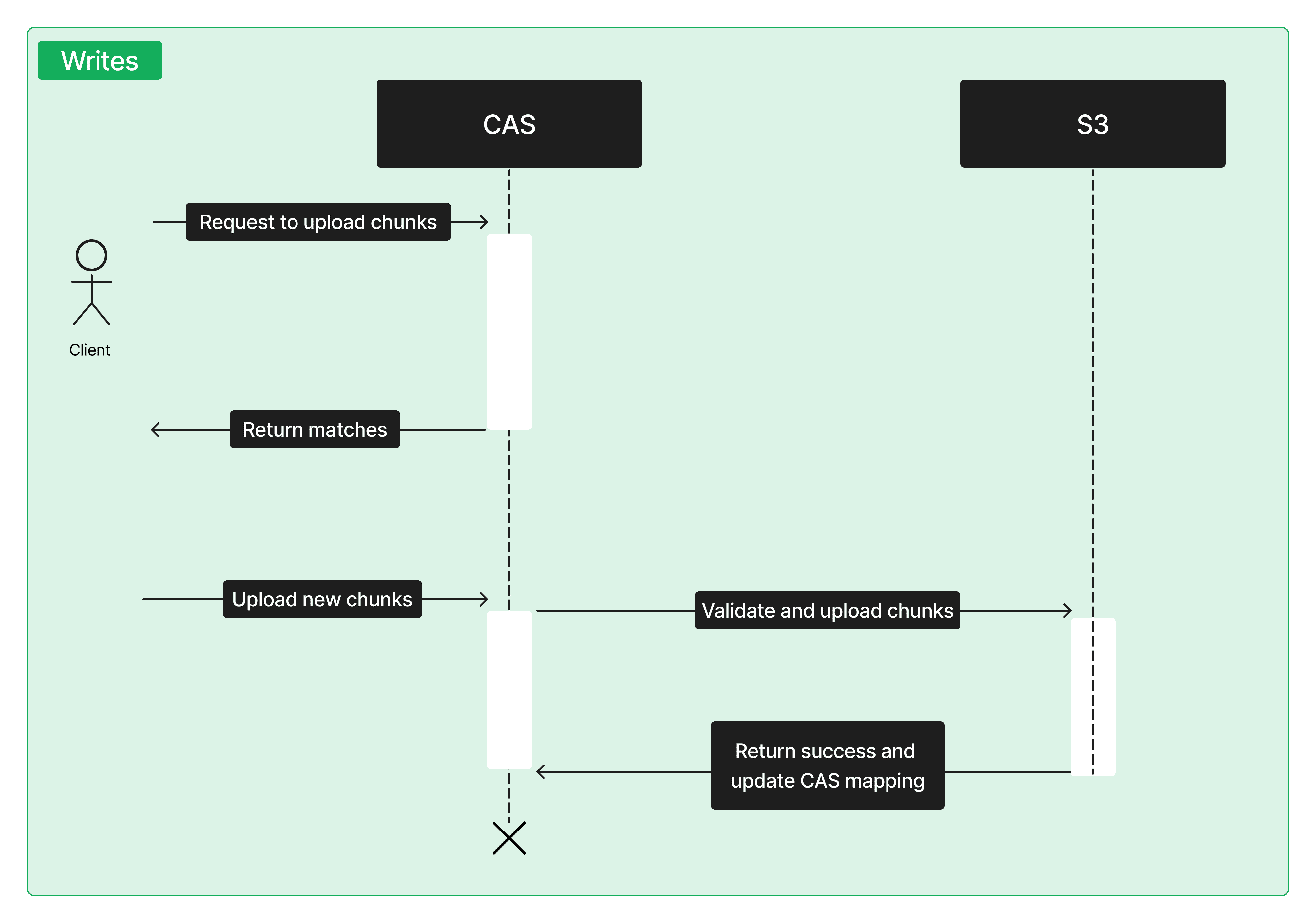
The write path is more complex to optimize upload speeds and provide additional security guarantees. Like reads, upload requests are routed to a CAS server, but instead of querying at the file level we operate on chunks. As matches are found, the CAS server instructs the client (e.g., huggingface_hub) to transfer only the necessary (new) chunks. The chunks are validated by CAS before uploading them to S3.
There are many implementation details to address such as network constraints and storage overhead which we’ll cover in future posts. For now, let's look at how reads currently look. The first diagram below show the read and write path as they currently look today:
Meanwhile, in the new design, reads will take the following path:
and finally here is the updated write path:
By managing files at the byte level, we can adapt optimizations to suit different file formats. For instance, we have explored improving the dedupeability of Parquet files, and are now investigating compressing tensor files (e.g., Safetensors) which have the potential to trim 10-25% off upload speeds. As new formats emerge, we are uniquely positioned to develop further enhancements that improve the development experience on the Hub.
This protocol also introduces significant improvements for enterprise customers and power users. Inserting a control plane for file transfers provides added guarantees to ensure malicious or invalid data cannot be uploaded. Operationally, uploads are no longer a black box. Enhanced telemetry provides audit trails and detailed logging, enabling the Hub infrastructure team to identify and resolve issues quickly and efficiently.
Designing for Global Access
To support this custom protocol, we need to determine the optimal geographic distribution for the CAS service. AWS Lambda@Edge was initially considered for its extensive global coverage to help minimize the round-trip time. However, its reliance on Cloudfront triggers made it incompatible with our updated upload path. Instead, we opted to deploy CAS nodes in a select few of AWS’s 34 regions.
Taking a closer look at our 24-hour window of S3 PUT requests, we identified global traffic patterns that reveal the distribution of data uploads to the Hub. As expected, the majority of activity comes from North America and Europe, with continuous, high-volume uploads throughout the day. The data also highlights a strong and growing presence in Asia. By focusing on these core regions, we can place our CAS points of presence to balance storage and network resources while minimizing latency.
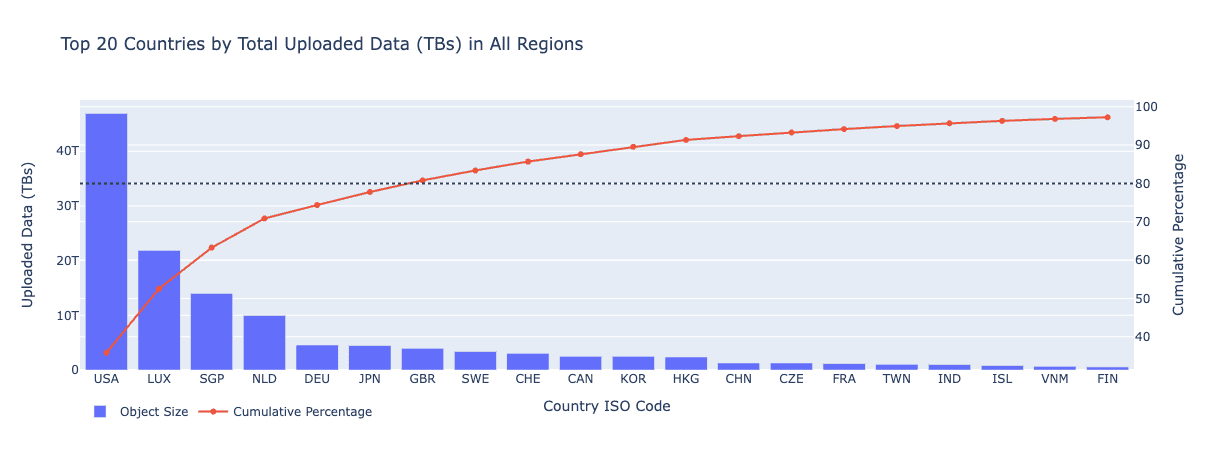
While AWS offers 34 regions, our goal is to keep infrastructure costs reasonable while maintaining a high user experience. Out of the 88 countries represented in this snapshot, the Pareto chart above shows that the top 7 countries account for 80% of uploaded bytes, while the top 20 countries contribute 95% of the total upload volume and requests.
The United States emerges as the primary source of upload traffic, necessitating a PoP in this region. In Europe, most activity is concentrated in central and western countries (e.g., Luxembourg, the United Kingdom, and Germany) though there is some additional activity to account for in Africa (specifically Algeria, Egypt, and South Africa). Asia’s upload traffic is primarily driven by Singapore, Hong Kong, Japan, and South Korea.
If we use a simple heuristic to distribute traffic, we can divide our CAS coverage into three major regions:
us-east-1: Serving North and South Americaeu-west-3: Serving Europe, the Middle East, and Africaap-southeast-1: Serving Asia and Oceania
This ends up being quite effective. The US and Europe account for 78.4% of uploaded bytes, while Asia accounts for 21.6%.
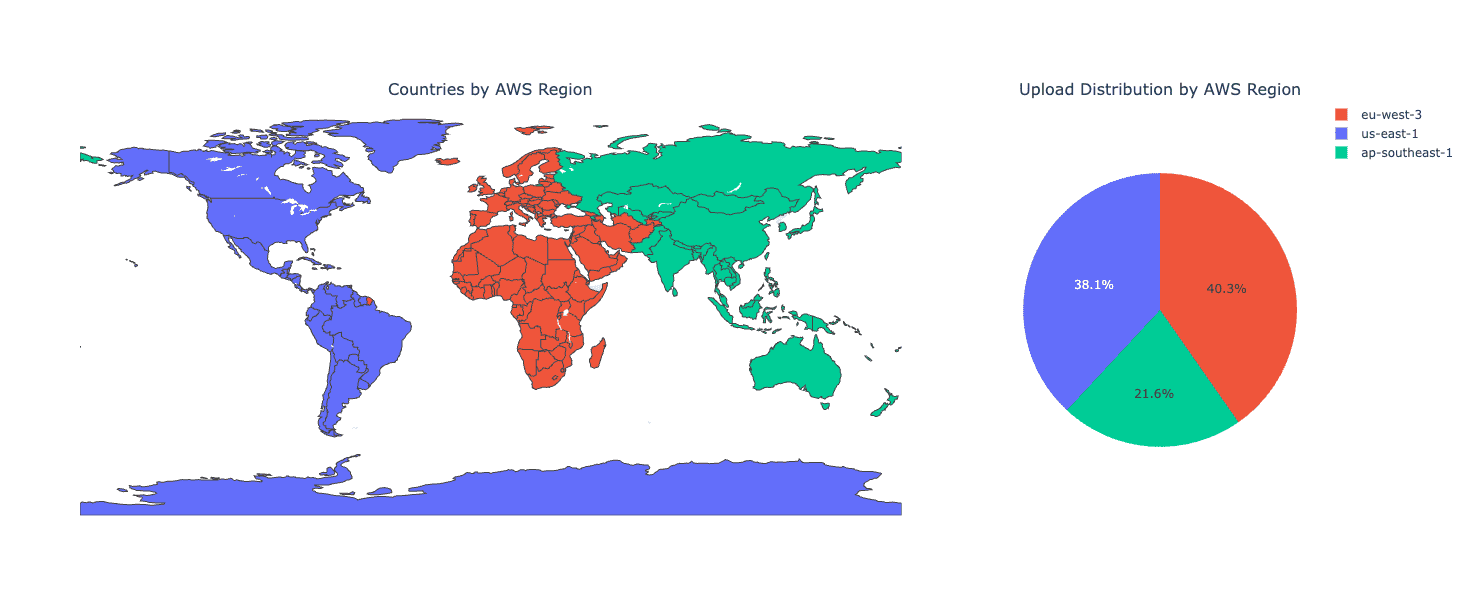
This regional breakdown results in a well-balanced load across our three CAS PoPs, with additional capacity for growth in ap-southeast-1 and flexibility to scale up in us-east-1 and eu-west-3 as needed.
Based on expected traffic, we plan to allocate resources as follows:
us-east-1: 4 nodeseu-west-3: 4 nodesap-southeast-1: 2 nodes
Validating and Vetting
Even though we’re increasing the first hop distance for some users, the overall impact to bandwidth across the Hub will be limited. Our estimates predict that while the cumulative bandwidth for all uploads will decrease from 48.5 Mbps to 42.5 Mbps (a 12% reduction), the performance hit will be more than offset by other system optimizations.
We are currently working toward moving our infrastructure into production by the end of 2024, where we will start with a single CAS in us-east-1. From there, we’ll start duplicating internal repositories to our new storage system to benchmark transfer performance, and then replicate our CAS to the additional PoPs mentioned above for more benchmarking. Based on those results, we will continue to optimize our approach to ensure that everything works smoothly when our storage backend is fully in place next year.
Beyond the Bytes
As we continue this analysis, new opportunities for deeper insights are emerging. Hugging Face hosts one of the largest collections of data from the open-source machine learning community, providing a unique vantage point to explore the modalities and trends driving AI development around the world.
For example, future analyses could classify models uploaded to the Hub by use case (such as NLP, computer vision, robotics, or large language models) and examine geographic trends in ML activity. This data not only informs our infrastructure decisions but also provides a lens into the evolving landscape of machine learning.
We invite you to explore our current findings in more detail! Visit our interactive Space to see the upload distribution for your region.
This post was originally published on the Hugging Face blog. Follow our team on Hugging Face to keep up with all new updates as we share our learnings on scaling CDC across globally distributed repositories, balancing network performance, privacy boundaries, and parallelizing our chunking algorithm.
Share on


