December 14, 2023
XetCache: Caching Jupyter Notebook Cells for Performance & Reproducibility


My Problem with Notebooks
While working on the “You do not need a Vector Database” article, I ran into a very common problem: doing long running tasks in a notebook. It is very annoying to run a cell which queries OpenAI 10,000 times… then accidentally overwrite the output variable.
A common desire for notebooks, is the ability to undo:
It is very easy to accidentally overwrite and modify (expensive) state
The work needed to read and store the state from disk is really ugly.
It is hard to keep all those disk state and cell state in sync: when do you rerun a cell? which file contains what?
Fundamentally, it is hard to organize a notebook so that I can use it both for experimentation, and be able to execute it efficiently straight from top to bottom.
This has always been one of my greatest frustration with working with notebooks.
My Solution
After some experimentation, I think I have a better way. Undo, or rewinding state, is the wrong way to think about the problem. The right way is to enable redo: to make re-running cells inexpensive and allow you to easily maintain notebook top to bottom execution.
The way to do this is simply using memoization, i.e. to cache the outputs of a function so that the next time it is called with the same inputs, we can simply return it from the cache. (Coincidentally, I was just working on Advent of Code 2023 Day 12… where the solution involves memoization too.)
This idea seems to be pretty obvious, but somehow I have not come across a package to do exactly what I need. The two I have came across — ipython-cache and cache-magic — require either explicit filename management or do not take input state into consideration.
So today we are open sourcing the xetcache library, an actual memoization system for data science notebooks.

Using XetCache Locally
All you need to do is run pip install xetcache from your command line and then run import xetcache at the start of your notebook.
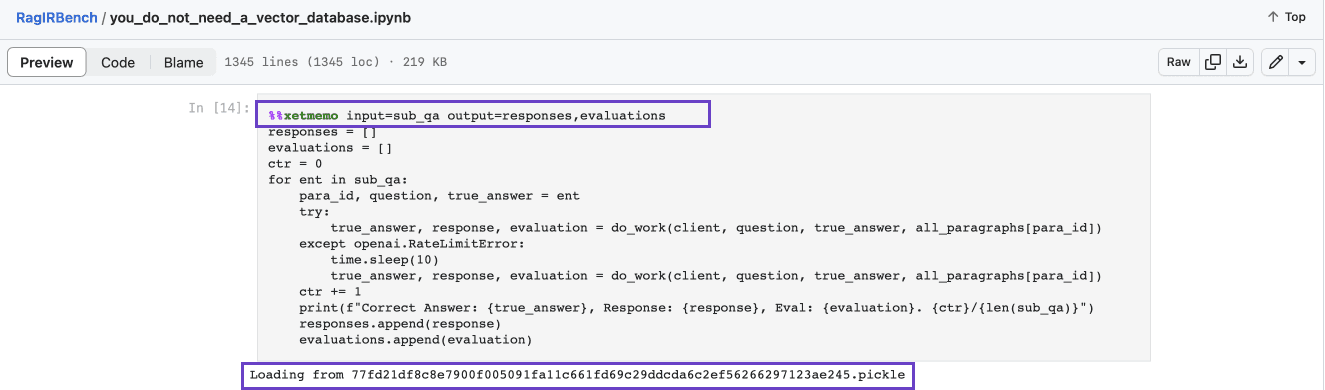
Then in any cell, we can use the xetmemo cell magic, specify the inputs we depend on and the outputs to cache.
And thats it! Future runs of the same cell will automatically load from cache.
The cache will automatically take into consideration both the contents of the input variable as well as the code in the cell. Any changes will trigger re-computation. You can even include other functions (clean_data()) you depend on as part of the input! This way if the function were to get modified, the computation will be re-triggered as well.
You can find lots of examples in the benchmarking notebook I used for my You Don’t Need a Vector Database post. By default, the cache is written to a local xmemo/ folder — cached pickle files are loaded back on re-runs as shown in the screenshot below.
Other Features
XetCache also support a few other usage scenarios such as decorators or function call memoization. Here’s an example of both of these:
Check out the documentation in the XetCache GitHub page for more details.
Help us Improve XetCache
XetCache is currently in alpha and can still be improved significantly:
Recursive tracking of function dependencies
Automatically inference of cell closures
Dependency tracing
Alternate storage format for small values
Faster hashing
Storage of displayed outputs
… and many others!
We think XetCache fills a much needed gap in the notebook experience. If you want to discuss ideas for improvement or want to contribute, please open issues in the GitHub repo.
Share on


